
A major Cloudflare outage on 18 November caused widespread service disruptions across the United Kingdom, with users in London reporting difficulties accessing X (formerly Twitter), Spotify, Facebook, Instagram, ChatGPT and numerous news websites. Instead of loading normally, many platforms displayed error messages or failed to connect entirely, reports The WP Times.
The disruption affected several UK-based services that rely on Cloudflare’s global infrastructure to stabilise traffic and protect against cyberattacks.
Cloudflare’s network is used to mitigate DDoS attacks, balance heavy traffic loads and ensure uninterrupted delivery of online content. Because a significant portion of the modern internet depends on its services, even a single internal malfunction led to simultaneous failures across unrelated websites and apps.
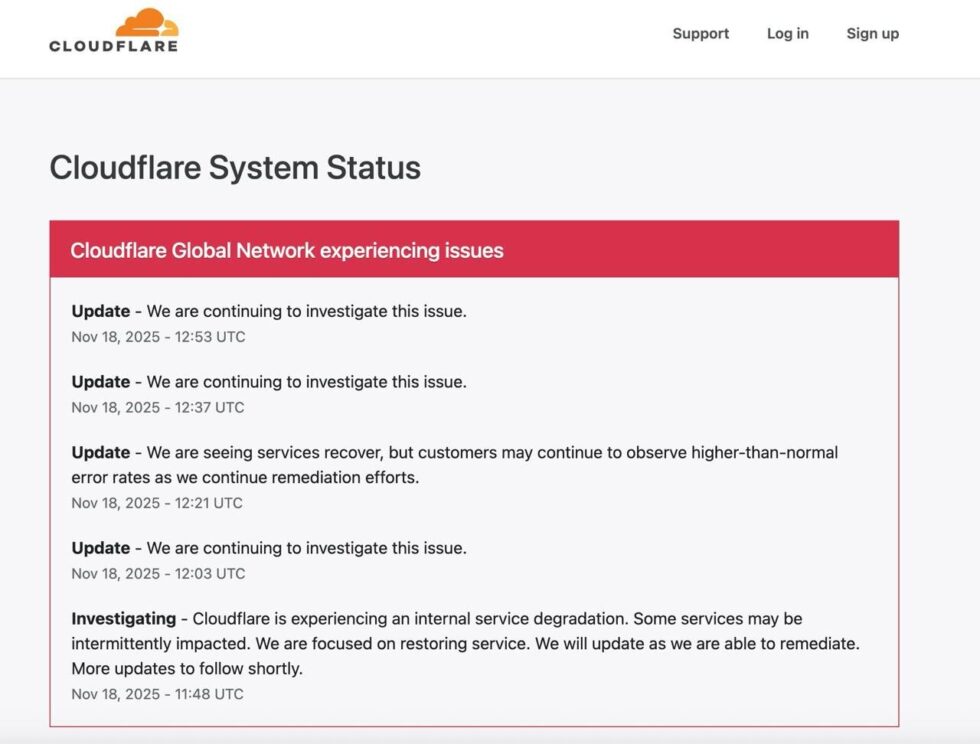
In London and other major UK cities, the first issues were observed shortly after 11:30 local time. Cloudflare confirmed publicly that it was investigating a problem impacting “numerous customers” worldwide. The incident was so extensive that DownDetector — the website used to track large-scale outages — became unstable itself, making the scope of the disruption harder to assess in real time.
Which services went down in the UK
Across the United Kingdom — especially in London — users reported problems with:
- X (Twitter) – timelines failed to refresh, login issues
- Facebook – pages loaded slowly or produced errors
- Instagram – difficulties opening profiles, posts and stories
- Spotify – unstable streaming and connection failures
- ChatGPT – service unavailable, “network error” messages
- Discord – message syncing issues for UK servers
- GitHub Pages and corporate websites relying on Cloudflare CDN
- Several British online media outlets experiencing partial or total downtime
- Some London-based e-commerce shops, especially those using Cloudflare caching and security layers
Service restoration across the UK occurred gradually, with some London boroughs affected longer due to regional traffic rerouting.
The company later acknowledged a wave of 500-level errors and partial downtime across its Dashboard and API systems. Engineers began restoring normal operations, but many UK users continued to encounter broken pages, delayed loading or complete inaccessibility of key sites for several hours.
By 15:45 UK time, Cloudflare announced the outage had been resolved. In a statement to TechRadar, the company explained that at 11:20 UTC it detected an unexpected surge of “unusual traffic” affecting one of its services. This sudden spike disrupted routing for part of the global network. The exact source of the abnormal traffic remains unknown.
Recent disruptions highlight how heavily today’s internet infrastructure depends on only a handful of large providers. Just weeks earlier, an Amazon Web Services outage caused similar global issues, demonstrating how a single failure at a major provider can impact millions of users simultaneously.
Read about the life of Westminster and Pimlico district, London and the world. 24/7 news with fresh and useful updates on culture, business, technology and city life: Is the rapid sell-out of the "Pocket" case a sign of Apple's pricing power

